文字コードはUTF-8? UTF-8N?
- 2014-01-30
- スラスラわかるHTML&CSSのきほん
- css / html / text-encoding / utf-8

HTMLやCSSファイルは、現在では特殊な事情がない限り、文字コードをUTF-8形式で保存します。ところで、UTF-8形式で保存する際に「UTF-8」と「UTF-8N」という、似たような2つの選択肢が出てくるテキストエディタがあります。「この違いはなんだ?どちらを選んだらよいのか」という質問を読者の方からいただきました。たしかに混乱するところなので、ここでお答えします。
『スラスラわかるHTML&CSSのきほん』p.37〜42
本書で紹介しているTeraPadを含む、文字コードの選択肢にUTF-8とUTF-8Nがあるタイプのテキストエディタでは、HTMLやCSSファイルの保存時に必ずUTF-8Nを選んで保存してください。
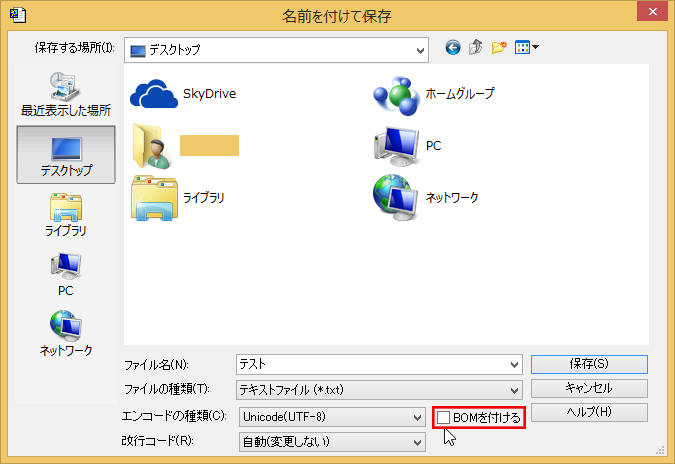
また、サクラエディタや秀丸エディタなど、選択肢にUTF-8しかないタイプのテキストエディタではUTF-8を選びます。こうした、選択肢がUTF-8しかないエディタでは、ファイル保存時のダイアログに[BOM]や[BOMを付ける]などというチェックボックスがあるかもしれません。このチェックボックスのチェックが外れていることを確認してから保存してください。
HTMLドキュメント内で文字コードを指定するときは、たとえ「UTF-8N」を選んで保存していたとしても、<meta charset="UTF-8">と書きます。<meta charset="UTF-8N">と書いてはいけません。参考までに、HTMLドキュメントの冒頭部は次のようになります。
<!doctype html> <html> <head> <meta charset="UTF-8"> <title>KUJIRA cafeへようこそ</title> </head> <body> ...
以上が、HTMLやCSSファイルを作成するときの正しい保存のしかたと、<meta charset>タグの書き方です。ここから先は少し詳しい背景説明をします。難しく感じるかもしれませんし、知らなくてもHTMLは書けますので、興味のある方だけお読みください。
さて、「UTF-8」は国際的に認められた正式の文字コード形式です。HTMLのキャラクターセット(文字コード)を指定するときも「UTF-8」を使います。
ところが、UTF-8Nという文字コードはありません。HTMLの<meta charset>にUTF-8Nと指定することもありません。UTF-8Nは、「BOMが付いていないUTF-8」を示す便宜的な名称です。おもに日本製のテキストエディタの一部がこの名称を使っているにすぎません。
それでは、このUTF-8Nとはいったいどういうものなのでしょう?
UTF-8という文字コード形式の規格では、「テキストデータの先頭に、文字コードを識別できるようBOMを付けてもよい」と定めています。そういう規格があるので、テキストエディタでテキストを保存するときに、BOMを付けるのか付けないのか選べるようになっているのです。
現在、UTF-8はBOMを付けないで保存するのが一般的です。昔のアプリケーションの中には、BOMが付いていないと文字コードの識別に失敗して、ファイルを開くときに文字化けしてしまうものもありましたが、今はそういうことはまずありません。むしろ、BOMが付いているとかえって問題が起こる場合もあるので、とくにHTMLやCSSファイルを保存するときは、絶対にBOMを付けません。
BOMは、Byte Order Mark(バイトオーダーマーク)の略で、「このテキストファイルの文字コードはUTF-8だよ」とコンピュータに知らせるためにファイルの先頭に付ける、人間の目には見えないデータです。
ここですこし、UTF-8形式のファイルの中身を見てみましょう。『スラスラわかるHTML&CSSのきほん』で作成するindex.htmlをテキストエディタで開くと、最初の数行はこのようになっているはずです。
<!doctype html> <html> <head> ...
これは、人間の目に見えるindex.htmlの最初の3行です。この3行、実は、コンピュータには次のように見えています。
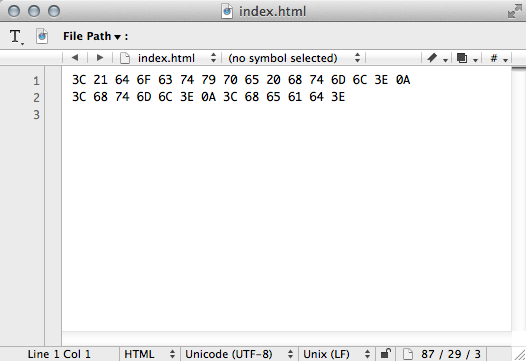
よくわからなくてなんとなく恐ろしい数字とアルファベットの羅列ですが、これが『スラスラわかる〜』で作成したindex.htmlの最初の3行ぶんのデータです。コンピュータはこの羅列を解釈して、最初から順に「3C」を「<」に、「21」を「!」に、「64」を「d」に……と、人間が見てわかる文字に変換して表示します(ここまでで最初の3文字「<!d」になる)。このindex.htmlは「BOMなし(TeraPadの選択肢ではUTF-8N)」で保存したファイルです。
よくわからなくて恐ろしいついでに、少し違う別のファイルも見てください。
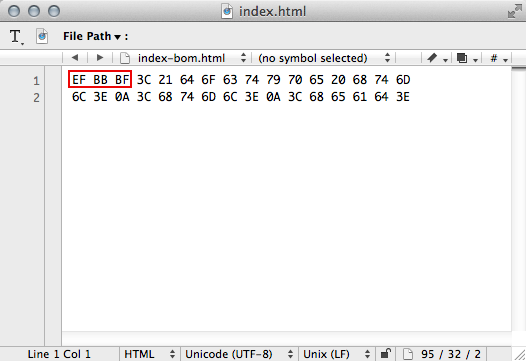
これも『スラスラわかる〜』で作成したindex.htmlの最初の3行ですが、「BOM付き(TeraPadの選択肢ではUTF-8)」で保存したUTF-8形式のファイルです。冒頭の囲んだ部分を除けば、それ以降は先の例と全く同じです。この囲んだ部分が「バイトオーダーマーク(BOM)」で、コンピュータにだけ見えているアルファベットの羅列です。
冒頭部分が「EF BB BF」で始まるファイルは「UTF-8形式のテキストデータである」と規格で定められていて、このアルファベットの羅列ことを、BOMと呼びます。昔のアプリケーションの中には「EF BB BF」がないとUTF-8形式を認識できないものがありましたが、現在のアプリケーションは、BOMを使用せず、それ以降の数字とアルファベットの羅列のパターンなどから文字コードを識別しています。そのためBOMは不要です。
<meta charset="UTF-8">と記述します。 Bootstrap 5のスターターテンプレートの使い方
2021-02-26
Bootstrap 5のスターターテンプレートの使い方
2021-02-26
 CSSで変数を使う var()
2019-12-17
CSSで変数を使う var()
2019-12-17

